

Faker.js Vs Smock-It: Which Mock Data Generator Is Right for You?
Testing isn’t complete unless it covers various conditions, scenarios, or user roles. However, using real users or production data is often impractical or even risky. This is where realistic test data plays an important role. It bridges the gap between limited-scope testing and comprehensive testing that mirrors real-world usage.
To create test data, QAs often turn to test data generation tools. Today, we’re comparing two such tools: Faker.js, a widely used open-source library, and Smock-it, a Salesforce Test Data Generator. We’ll explore how each tool works, their key differences, and which one is better suited to your specific testing needs.
Blog Outline:
What is Faker.js?
How to Install Faker.js
How Faker.js Generates Test Data
Key Features of Faker.js
What is Smock-it?
How to Install Smock-it
How Smock-it Generates Test Data
Key Features of Smock-it
Faker.js vs Smock-it: Which One Fits Where?
Conclusion
This blog is part of our ongoing mock data tool comparison series. We’ve also compared:
What is Faker.js?
Faker.js is a JavaScript library designed to generate realistic fake data for testing and development. It can create various data types, including names, addresses, emails, phone numbers, and more.
Originally launched as an open-source project, the library was discontinued in 2022 but has since been revived and is now actively maintained through community forks. It remains a valuable tool for mocking APIs, seeding databases, and prototyping applications in Node.js, React, and other JavaScript environments.
How to Install Faker.js
To start using Faker.js in your project, you’ll need to install it using npm, the Node.js package manager. Run the following command in your project directory:
npm install @faker-js/faker
Once installed, you can import it into your code like this:
import { faker } from '@faker-js/faker';
By default, this import works in the English locale. Faker.js supports 70+ locales. For example, to generate Spanish data, use:
import { fakerES as faker } from '@faker-js/faker';
Now you're ready to generate fake data for testing and development.
Note: While this guide focuses on the JavaScript version (Faker.js), similar libraries are available in other languages, such as Python, Ruby, PHP, and more, offering fake data generation across multiple tech stacks.
How Does Faker.js Generate Test Data?
Faker.js generates test data using a wide range of prebuilt methods organized into modules such as person, location, internet, commerce, date, and more. Each module includes methods that return randomized values designed to mimic real-world data formats.
For instance, the person module can generate full names and job titles, while the internet module creates emails, usernames, and IP addresses.
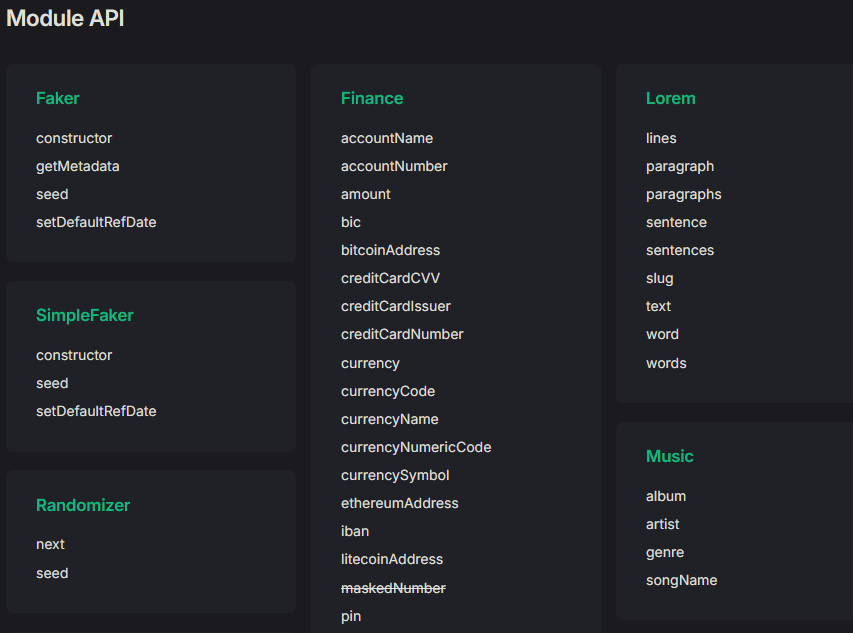
So, to generate any random data using Faker.js, follow the pattern: faker.module.method()
For example:
To generate a person’s name:
faker.person.fullName()To generate a random song name:
faker.music.songName()
This consistent pattern and modular structure make it easy to explore different types of fake data across categories like people, music, commerce, location, and more.
Example: Generate Complete Fake Person Data
Now, to generate a complete set of fake personal details, such as name, email, address, phone number, and job title, you can use the following code snippet:
import { faker } from '@faker-js/faker';
const person = {
name: faker.person.fullName(),
email: faker.internet.email(),
address: faker.location.streetAddress(),
phone: faker.phone.number(),
jobTitle: faker.person.jobTitle(),
};
console.log(person);
The output will resemble:
{
"name": "Lillian Anderson",
"email": "lillian.anderson@example.com",
"address": "1234 Elm Street",
"phone": "(123) 456-7890",
"jobTitle": "Marketing Specialist"
}
Since Faker generates random values on each execution, the output (like names) will change every time you run it. However, here’s the catch: Faker uses a limited set of predefined values. So while the data appears random, it's not truly unique. To understand this better, let’s take a quick look under the hood.
How Faker Works Internally
Predefined Lists: Faker relies on internal datasets for things like first names, last names, job titles, countries, and more. These lists are often locale-specific. For example, the English locale will have a different pool of names compared to Spanish or Japanese.
Random Combination: Rather than selecting full names from a static list, Faker typically creates them by combining values from multiple smaller pools. For example:
faker.person.fullName() is usually a combination of faker.person.firstName() and faker.person.lastName().
This method allows hundreds (or even thousands) of possible combinations, even when working with relatively small datasets.
Key Features of Faker:
Extensive Data Types
Generate fake names, addresses, emails, phone numbers, images, credit card details, company names, lorem ipsum text, and more.Localization Support
Faker supports multiple locales, allowing you to generate data in various languages and region-specific formats (e.g., US, UK, India, etc.).Consistent Data with Seeding
You can seed the generator for consistent and repeatable fake data generation, which is useful for testing.Testing Framework Compatibility
Faker works seamlessly with popular testing frameworks like Playwright, Cypress, and Jest, making it ideal for end-to-end and integration testing.
What is Smock-it?
Smock-it is a Salesforce-native CLI tool designed specifically for generating realistic mock data within Salesforce orgs. Unlike Faker.js, which is a general-purpose JavaScript library, Smock-it is built entirely around the Salesforce ecosystem, making it a better fit for developers and testers working on or validating Salesforce projects.
It addresses the common challenges QA engineers face when relying on manual scripts to create test records. With just a few commands, users can generate large volumes of data across both standard and custom objects.
How to Install Smock-it
Installing Smock-it is straightforward. You only need to have the Salesforce CLI and Node.js (version 18 or later) installed on your system.
Once requirements are fulfilled, open your terminal and run the following command:
sf plugins install smock-it
This command will install the Smock-it plugin into your Salesforce CLI.
To verify the installation, run:
sf plugins
If Smock-it was installed successfully, you’ll see it listed along with the installed version.
Refer to this dedicated guide on how to install Smock-it.
How Does Smock-it Generate Test Data?
Smock-it uses its own built-in data library to generate realistic and unique mock data. Creating test data is as simple as installing the tool. All you need to do is define your requirements using a JSON template.
Once your template is ready, a single command can generate large volumes of 100% unique data.
Getting Started with Template Creation
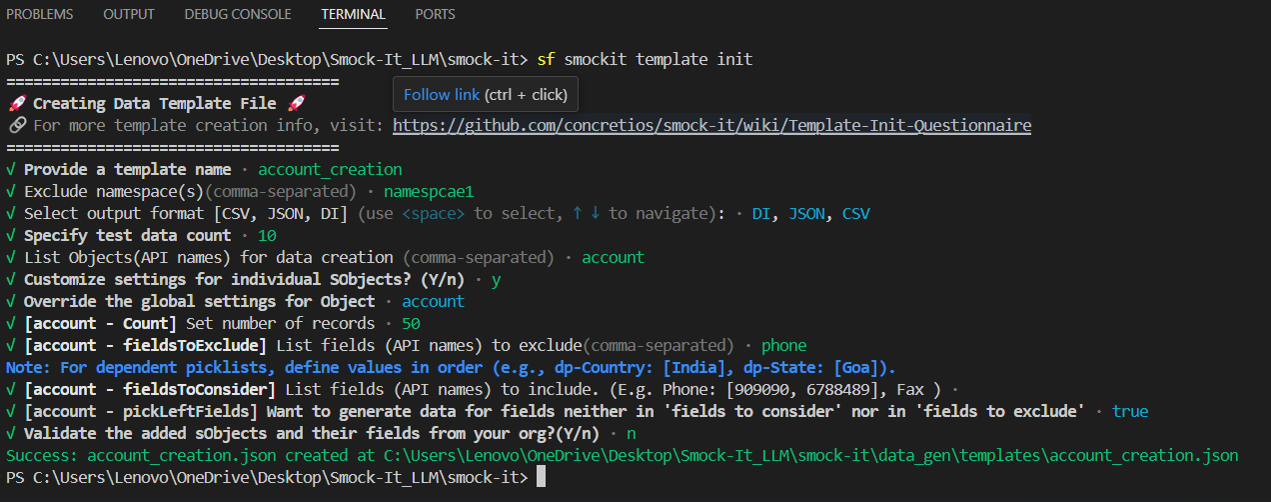
To begin, initialize your data template by running the following command in your terminal:
sf smockit template init
This will launch an interactive questionnaire to help you configure your data generation template. You'll be prompted to provide the following details:
Template name
Exclude namespace(s) (comma-separated)
Select output format (CSV, JSON, or DI using arrow keys and spacebar)
Test data count
Objects to generate data for (comma-separated API names)
Customize settings for individual SObjects? (Y/n)
Validate the selected SObjects and their fields from your org? (Y/n)
To dive deeper into template creation, read our guide on How to Create a Test Data Template in Smock-It.
Once you've answered the questionnaire, Smock-it will save your template in JSON format within the data-gen-template directory. You can then use it to generate mock data instantly with a single command or save it for future use.
Final Step: Generate the Data
Simply run the following command to generate your test data.
sf smockit data generate -t <templateFileName> -a <aliasOrUsername>
This command uses your saved template to create mock data based on the inputs you provided earlier. The data will be generated in the output format you selected, CSV, JSON, or DI (Direct Insert).
Note: If you choose DI as the output format, the data will be directly inserted into the authenticated Salesforce org specified in the command.
Key Features of Smock-it
Native Data Library
Smock-it comes with a built-in data library capable of generating not just random but truly unique records, scaling up to 300,000 records. Making it the best alternative to Faker for bulk data needs.Easy Template-Based Generation
Define your data needs once by simply answering a set of easy questions. Smock-it then saves it as a reusable JSON template for repeatable data generation.Multi-Org Data Upload
The same mock data can be generated once and uploaded to multiple Salesforce orgs, making it ideal for environments like dev, QA, and staging.Flexible Output Options
Choose from CSV, JSON, or DI (Direct Insert) formats depending on your workflow. DI supports direct data push to authenticated Salesforce orgs.Dependent Picklist Handling
Smock-it supports dependent picklists by allowing you to define controlling and dependent values directly in your templates using the dp- prefix. This ensures accurate data generation that mirrors real-world field relationships in Salesforce.
Which One Fits Where?
Both Faker.js and Smock-it are powerful tools for generating mock data, but they differ significantly in capabilities, ease of use, and intended use cases.
Smock-it is specifically designed for Salesforce, making it ideal for scenarios where you need test data aligned with Salesforce's standard or custom objects. It comes with a native in-built data library and supports direct data insertion into Salesforce orgs. The process is simple: just answer a few questions, and Smock-it handles the rest, with no complex scripting or setup required.
Faker.js, on the other hand, is a general-purpose JavaScript library suited for web development, API testing, and frontend/backend applications outside of Salesforce. However, it comes with a few limitations. Its predefined data pools are limited, take animal.type, for instance, which only includes 44 animal types.
Additionally, for beginners, generating complex, condition-based data can be overwhelming due to its less intuitive syntax, especially when compared to Smock-it's template-based approach.
In short, use Smock-it when you need an easy, Salesforce-focused solution for generating test data. Choose Faker.js when you're working on non-Salesforce applications and are comfortable writing code to customize data.
Let’s Talk

Drop us a note, we’re happy to take the conversation forward